Mastering AWS Data Pipeline: A Comprehensive Guide
Oct 22, 2025
Did you know 97% of big companies face data integration problems? AWS Data Pipeline is a strong tool for managing and processing data in the cloud.
Today, companies create huge amounts of data that need to move and change smoothly. AWS Data Pipeline, part of Amazon ETL, helps automate complex data tasks across various systems.
This guide will dive into AWS Data Pipeline’s details. It will cover its setup, what it can do, and how to use it well. It’s great for data engineers, cloud architects, and business leaders looking to improve their data handling.
Key Takeaways
- AWS Data Pipeline makes complex data tasks easier
- It helps move data reliably between different AWS services
- It automates scheduling and running data workflows
- It offers scalable solutions for big data management
- It cuts down on manual work in data pipelines
Introduction to AWS Data Pipeline
Managing complex data workflows can be tough for businesses. They need efficient cloud processing solutions. AWS Data Pipeline is a powerful web service that helps manage data across different computing environments.
What is AWS Data Pipeline?
AWS Data Pipeline is a cloud service that helps organizations process and move data. It works with various AWS compute and storage services. This platform supports cloud data workflow management, making data processing reliable and scalable.
Key Features of AWS Data Pipeline
- Supports multiple data sources and destinations
- Enables automated AWS batch processing
- Integrates with AWS services like EC2, S3, and RDS
- Provides flexible scheduling options
- Offers built-in fault tolerance and retry mechanisms
Benefits of Using AWS Data Pipeline
Organizations using AWS Data Pipeline see big improvements in data management. It simplifies complex workflow orchestration. It also reduces manual intervention and ensures consistent data processing.
“AWS Data Pipeline transforms how businesses handle cloud data workflows, making complex processing tasks more manageable and efficient.”
By automating data movement and transformation, companies can focus on insights. They don’t have to deal with the complex data infrastructure challenges.
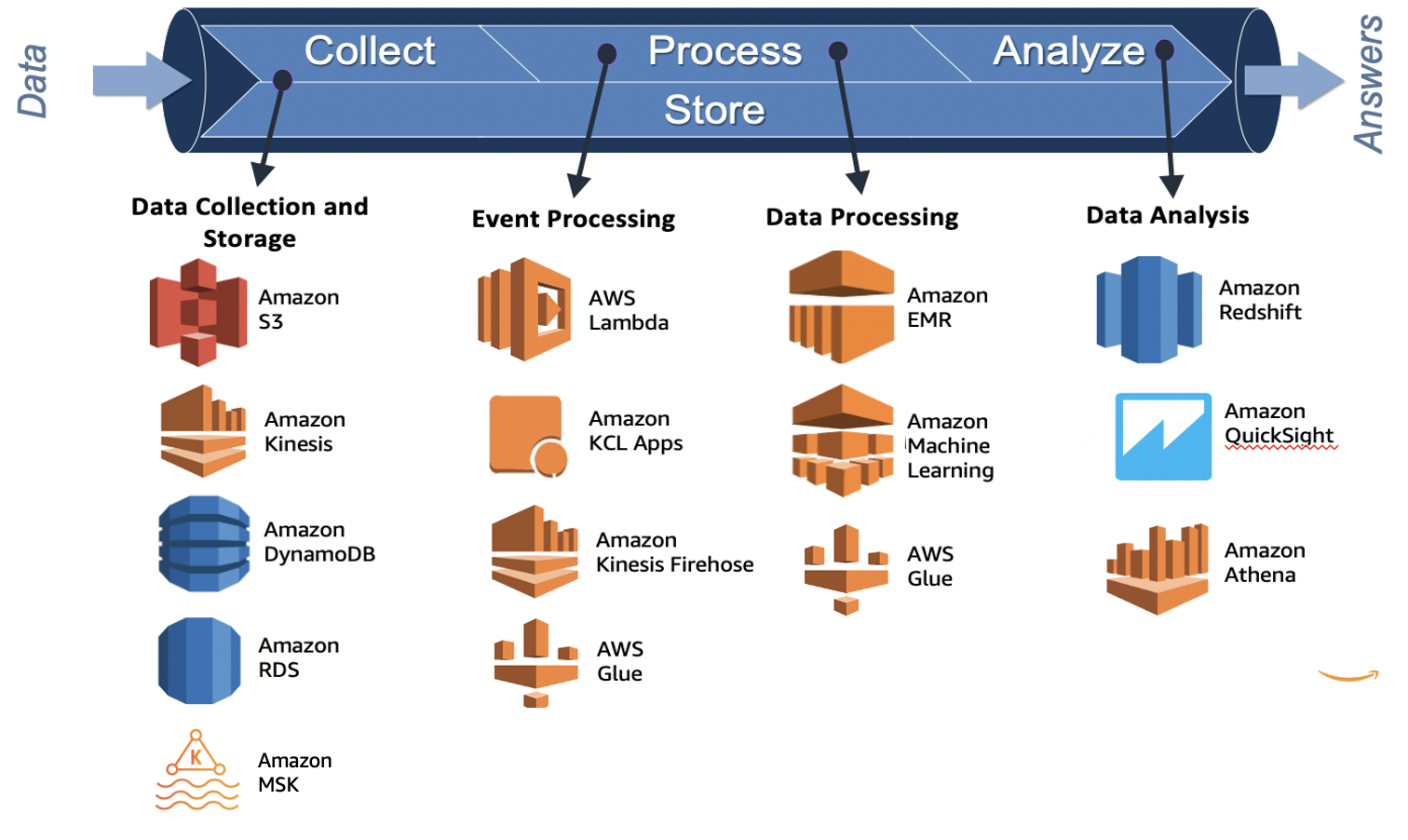
Understanding Data Workflows
Data workflows are key to managing data well in cloud computing. They help move, process, and change data between systems. In AWS, they make data integration smooth, helping companies handle complex data tasks.
Today’s businesses need smart data strategies to get the most from their data. AWS automated data transfer offers a solid way to build these complex data paths.
What is a Data Workflow?
A data workflow is a series of steps for data processing. It shows how data moves and changes between systems. It has:
Components of a Data Workflow
Good data workflows in AWS have key parts:

Examples of Data Workflows
Data workflows in real life show AWS’s power. For example, in retail analytics, sales data from stores is gathered, changed, and put into a big data warehouse. This helps with business insights.
“Data workflows turn raw data into useful insights, helping make better decisions.” — AWS Services
Knowing these parts helps companies make better data plans. They can use cloud computing to its fullest.
Setting Up Your AWS Data Pipeline
Getting into serverless data movement needs a smart plan for AWS data flow. AWS Data Pipeline is a great tool for making data processing easier without a lot of setup.
Before you start making your pipeline, you need to get a few things right. You must build a strong base for managing your data well.
Essential Prerequisites for Pipeline Setup
- Active AWS account with the right permissions
- IAM roles set up for data pipeline access
- Known data sources and places to send data
- Clear idea of what your data workflow needs
Creating Your First Pipeline
Starting your first AWS Data Pipeline is a step-by-step process. First, figure out your main data sources and what changes you need to make.
Become a GitOps enabled professional by getting certified with the Linux Foundation.

- Log into AWS Management Console
- Go to AWS Data Pipeline service
- Click “Create New Pipeline”
- Set your pipeline’s name and description
- Connect your data sources
Pipeline Configuration Essentials
Good AWS data flow management needs careful settings. Think about these important details:
“The success of your data pipeline depends on thoughtful configuration and understanding of your specific data processing requirements.”
By following these steps, you’ll make a strong and effective data pipeline. It will help your organization with its data needs.
Core Components of Data Pipeline
AWS Data Pipeline is a key tool for managing complex data workflows. Knowing its main parts is key for setting up effective ETL automation on AWS. It helps in creating strong data migration pipelines.
Pipeline Definition: The Blueprint of Data Workflows
A pipeline definition is like a blueprint for your data processing plan. It shows the activities, data sources, and resources needed to move data well. Developers use JSON or the AWS Management Console to make these definitions. They set up the details for ETL automation on AWS.
Data Nodes: Mapping Your Data Ecosystem
Data nodes are key points in your data migration pipelines. They show where data comes from and goes to. This includes:
Schedule and Execution: Automating Data Workflows
The scheduling in AWS Data Pipeline lets you control when data is processed. You can set up:

Understanding these core parts helps organizations create scalable, efficient data systems with AWS Data Pipeline.
Data Sources and Destinations
AWS Data Pipeline is a powerful tool for moving data around. It helps organizations transfer and change data easily between different places. This makes data movement smooth and efficient.
It’s important to know what data sources and destinations are supported. This lets data experts connect various systems and platforms. It helps streamline data workflows.
Supported Data Sources
The AWS Data Pipeline works with many data sources, including:
- Amazon S3 storage buckets
- Amazon RDS databases
- Amazon DynamoDB
- On-premises relational databases
- External SQL databases
Common Data Destinations
Organizations can send their data to several places using the Amazon ETL service:
- Amazon Redshift data warehouses
- Amazon S3 storage
- Elastic MapReduce (EMR) clusters
- Amazon DynamoDB
- Custom database environments
Best Practices for Data Integration
To make data pipelines work better, follow these tips:
- Design modular and reusable pipeline components
- Implement robust error handling mechanisms
- Use appropriate data transformation techniques
- Regularly monitor pipeline performance
- Secure data transfer with encryption
“Effective data integration is about connecting the right sources to the right destinations with minimal friction.” — AWS Data Engineering Team
Knowing about data sources and destinations helps organizations use AWS Data Pipeline to its fullest. It leads to more efficient and smart data workflows.
Transforming Data with AWS Data Pipeline
Data transformation is key in today’s cloud data workflows. AWS Data Pipeline helps organizations manage and transform data efficiently. It uses batch processing to unlock insights from raw data.
Data transformation changes raw data into useful information. AWS Data Pipeline offers several ways to do this. It makes cloud data workflow management easier and faster.
Overview of Data Transformation
Data transformation includes several important steps:
- Cleaning and standardizing data formats
- Filtering and aggregating information
- Converting data types
- Enriching datasets with additional context
Using AWS Data Pipeline for ETL
AWS batch processing makes ETL operations precise. The pipeline supports various transformation methods:
- Custom scripting for complex transformations
- Integration with AWS Glue ETL jobs
- Leveraging Amazon EMR for large-scale data processing
Examples of Data Transformation Tasks
Real-world data transformation tasks include:
- Log file analysis: Cleaning and structuring web server logs
- Financial data normalization: Standardizing transaction records
- Customer data enrichment: Merging multiple data sources for insights
Robust data transformation strategies turn raw data into valuable assets. This drives informed decision-making and gives a competitive edge.
Monitoring and Logging in Data Pipeline
Effective AWS data flow management needs strong monitoring and logging.
Data pipelines are complex and need constant watch to work well. It’s key to know how to check and understand your pipeline’s health for good data integration in AWS.
Importance of Monitoring
Monitoring your AWS data pipeline gives you important insights. It helps you see how well the system is doing and spot any problems.
The main benefits are:
- Early detection of performance bottlenecks
- Identification of possible security risks
- Tracking data flow efficiency
- Ensuring consistent pipeline reliability
Tools for Monitoring
AWS has many strong monitoring tools for data integration in AWS:

Analyzing Pipeline Logs
Log analysis is key in AWS data flow management. It helps find problems, improve performance, and keep systems safe. Looking at logs regularly can stop problems before they affect your data pipeline.
“Monitoring is not just about tracking metrics, it’s about understanding the story behind the data.” — AWS Data Engineering Expert
With good monitoring and logging, companies can make sure their AWS data pipelines run smoothly. This means reliable and useful data integration.
Handling Data Security in AWS Data Pipeline
Data security is key in cloud environments for serverless data movement. AWS Data Pipeline has strong security to keep data safe during transfer and processing.
Companies need to have strong security plans to protect their data. Here are the main steps to keep data safe all the way through the workflow.
Data Encryption Techniques
Encryption is the main way to protect AWS data pipelines. AWS has several ways to keep data safe:
- Server-side encryption for data at rest
- Client-side encryption before sending
- SSL/TLS encryption for data in transit
Role-Based Access Control
AWS Identity and Access Management (IAM) helps control data transfer. Companies can set up specific permissions with:
- Predefined IAM roles
- Custom security policies
- Principle of least privilege
Best Practices for Security Compliance

Keep watching your AWS Data Pipeline and always be ready to act on security issues.
Error Handling and Troubleshooting
Managing errors well is key for ETL automation on AWS to work smoothly. Data migration pipelines need strong troubleshooting to keep data flowing without hitches. Knowing how to spot, fix, and prevent problems makes your cloud data processes more reliable.
Common Issues in Data Pipeline Operations
Developers often face many challenges with AWS Data Pipeline. Some common problems include:
- Permission and access configuration errors
- Network connectivity interruptions
- Resource allocation failures
- Data transformation inconsistencies
Debugging Tools and Strategies
AWS has great tools for debugging ETL automation. CloudWatch logs and pipeline execution history are key for finding and fixing issues. Developers can use these tools to:
- Track pipeline execution steps
- Analyze error messages
- Monitor resource utilization
- Implement automated error recovery mechanisms
“Effective error handling is not about preventing all failures, but about gracefully managing and learning from them.” — AWS Data Engineering Best Practices
Maintaining Pipeline Reliability
To keep data migration pipelines strong, use good error handling strategies. This means setting up retries, setting timeouts, and logging details. Regular checks and upkeep stop problems before they start.
Learning these error handling skills makes your ETL automation on AWS more solid and reliable.
Cost Management for AWS Data Pipeline
Managing expenses is key when using cloud services like AWS Data Pipeline. It helps you get the most value from your Amazon ETL service while keeping costs down.
It’s important to know how AWS Data Pipeline charges. This knowledge helps you control your data workflow costs. The service charges based on several factors that affect your spending.
Understanding Pricing Models
AWS Data Pipeline pricing has two main parts:
- Pipeline scheduling frequency
- Computational resources used
- Data transfer and storage needs
Cost Optimization Strategies
To cut down on costs with AWS Data Pipeline, try these strategies:
- Plan resource use well
- Choose the right instance types
- Use spot instances for cheaper processing
- Keep checking and tweaking pipeline settings
Monitoring Your Pipeline Costs
AWS has great tools for watching and understanding your Amazon ETL service costs. Use AWS Cost Explorer and detailed billing reports to see where your money goes.
By using these strategies, companies can manage and cut down their AWS Data Pipeline costs. They can keep their data workflows running smoothly and efficiently.
Advanced Features of AWS Data Pipeline
AWS Data Pipeline has powerful features that change how we manage cloud data. These features help developers make data processing smarter and more efficient. They make it easier for companies to handle AWS batch processing in new ways.
The advanced features of AWS Data Pipeline go beyond just moving data. They offer strong tools for complex data management and automated workflows.
AWS Lambda Integration
When AWS Lambda is used with Data Pipeline, it opens up new ways to process data. This mix lets developers:
- Run custom code in data workflows
- Apply complex data transformations
- Set up data processing based on events
Service Integration Strategies
AWS Data Pipeline works well with many AWS services. This makes it easy to build complete cloud data workflows. Key areas of integration include:

Scheduling and Automation
Advanced scheduling in AWS Data Pipeline gives developers control over when data is processed. They can set up:
- Jobs that run at regular times
- Workflows that start at specific times
- Complex rules for when tasks can run
Learning these advanced features helps companies build intelligent, scalable data processing systems. These systems can grow with the business.
Case Studies and Use Cases
AWS Data Pipeline changes how companies handle complex data tasks. By looking at real examples, businesses can learn a lot about using AWS for data. They can see how to move data automatically.
Successful Enterprise Data Management Implementations
Many companies from different fields have used AWS Data Pipeline to tackle big data problems. Here are some examples:
- Netflix: Made global content recommendation engine faster
- Airbnb: Made data warehousing and data syncing across regions easier
- Capital One: Improved financial data handling and risk management
Key Implementation Insights
What makes a successful AWS Data Pipeline project?
- A solid data integration in AWS setup
- Scalable data transfer tools
- Good error handling and monitoring
- Flexible scheduling and execution
Performance and Efficiency Outcomes
Companies using AWS Data Pipeline see big benefits:
- 50–70% less time spent on data processing
- Better data reliability and consistency
- Easier management of complex data workflows
“AWS Data Pipeline has changed how we manage data, making our operations smarter and more efficient.” — Tech Industry Leader
Conclusion and Next Steps
AWS Data Pipeline is a powerful tool for moving data without servers and managing data flows. As cloud tech grows, knowing how to use these tools is key for today’s businesses.
Our deep dive into AWS Data Pipeline shows its huge impact on tech. It’s clear the platform is flexible and strong in handling complex data tasks.
Key Takeaways
- Serverless data movement makes integrating cloud environments easy
- AWS data flow management offers scalable and efficient data solutions
- Staying up-to-date with cloud data tech is vital
Learning Resources
For those looking to improve their skills, here are some great resources:
- AWS Official Documentation — Detailed technical guides
- Online training sites with AWS certification courses
- Community forums and webinars
Future Outlook
AWS is always improving its data movement tools, aiming for more advanced features. The use of AI and machine learning in data pipelines is an exciting area to watch.
The future of cloud data management is about smart, adaptable, and seamless tech.
Those wanting to excel in these areas might look into getting cloud architecture certifications. This will help them stay on top in a fast-changing field.
FAQs About AWS Data Pipeline
Working with AWS Data Pipeline can lead to many questions. This section answers the most common ones. It helps you understand data migration pipelines better.
Top Questions About Data Migration Pipelines
Comprehensive Answer Guide
AWS Data Pipeline is a web service for moving data between AWS services. It helps with ETL automation on AWS. It offers a flexible way to create data-driven workflows.

Community Resources and Support
For more help with data migration pipelines, check out these resources:
- AWS Developer Forums
- Official AWS Documentation
- AWS Community Slack Channels
- Technical Webinars
Expert Tips for Troubleshooting
When using AWS Data Pipeline, always validate your pipeline configuration. Use AWS CloudWatch for monitoring and logging. Understanding error messages can make your ETL automation smoother.
“Mastering AWS Data Pipeline requires patience and continuous learning.” — AWS Cloud Experts
Final Thoughts
Businesses face a complex world of data management. The AWS Data Pipeline is a key tool for turning raw data into valuable insights. It’s more than a tech solution; it’s a way to manage data smartly, changing how companies use digital tools.
The aws data pipeline makes complex data tasks easier. It offers strong, growing solutions for all business sizes. Whether you’re a startup or a big company, this platform lets teams build advanced data systems easily.
Staying up-to-date is key in cloud computing and data engineering. As tech changes, people need to learn new skills and keep up with trends. The AWS world offers great chances for those who keep learning and using new data strategies.
Future tech like AI and machine learning will change data pipeline design. Companies that keep up with these changes will lead the way. By using AWS Data Pipeline and learning constantly, they can find new business insights and innovate.
Become a GitOps enabled professional by getting certified with the Linux Foundation.

Cloud InterviewACE. The best way to pass the Cloud Computing interviews. Period.
Get Certified with Digital Crest Institute today
Stay connected with news and updates!
Join our mailing list to receive the latest news, discounts and updates from our team.
Don't worry, your information will not be shared.
We hate SPAM. We will never sell your information, for any reason.